Mali G1-Ultra, Premium und Pro: Arm verdoppelt die Raytracing-Leistung der Mobile-GPUs

Als Bestandteil der neuen Lumex CSS Platform führt Arm neue Grafikeinheiten unter der etablierten Bezeichnung „Mali“ ein. Im Fokus der Ankündigung steht das Flaggschiff Mali G1-Ultra, dessen Raytracing-Leistung dank neuer Ray Tracing Unit doppelt so hoch ausfällt. Die Leistung bei Rasterisierung und die Effizienz steigen ebenso.
Mali bleibt Mali und Immortalis fliegt raus
Anders als bei dem Plattformnamen „Lumex“ und der Bezeichnung „C1“ für die neuen CPU-Kerne behält Arm für die aktualisierten Grafikeinheiten die bekannte Mali-Nomenklatur bei. Die Chip-IP-Entwickler aus Cambridge trennen sich für die Neuvorstellungen sogar wieder von der jüngsten Namenskreation „Immortalis“, mit der 2022 die erste Raytracing-GPU von Arm, die Immortalis-G715, ihre Premiere feierte.
Mali G1-Ultra bedingt 10 Kerne und Raytracing
Die neuesten GPUs für Smartphone-Prozessoren hören stattdessen wieder ausschließlich auf den Namen Mali. Als Mali G1-Ultra darf eine GPU mit mindestens 10 Kernen und Ray Tracing Unit der zweiten Generation (RTUv2) bezeichnet werden. Darunter positioniert Arm die Mali G1-Premium mit 6 bis 9 Kernen und klassischen Shader Cores ausschließlich für die Rasterisierung. Raytracing ist hier optional, aber bei weniger als 10 Kernen verhilft das Feature nicht zur Ultra-Bezeichnung. Als Mali G1-Pro werden die kleinsten Modelle mit 1 bis 5 Shader Cores bezeichnet.


Arm setzt 5. Generation GPU-Architektur fort
Mali G1-Ultra, G1-Premium und G1-Pro basieren erneut auf der 5. Generation der GPU-Architektur von Arm, die das Unternehmen 2023 mit der Immortalis-G720, Mali-G720 und Mali-G620 eingeführt hatte. Nach Raytracing vor drei Jahren war die größte Neuerung vor zwei Jahren das Deferred Vertex Shading (DVS). Letztes Jahr kamen der Fragment Prepass für ein effizienteres Rendering und die Option auf bis zu 24 Kerne hinzu.
Die gesteigerte Leistung im Überblick
Die neuen G1-Modelle bieten Arm zufolge eine doppelt so hohe Raytracing-Leistung, eine durchschnittlich 20 Prozent höhere Gaming-Leistung und eine ebenfalls 20 Prozent höhere AI-Leistung. Für jeden gerenderten Frame habe Arm zudem den Energieverbrauch der GPU um 9 Prozent reduzieren können.
Ray Tracing Unit der 2. Generation
Das Unternehmen erwartet einen steigenden Raytracing-Anteil in Spielen und Benchmarks, daher bereitet es die eigenen GPUs mit dem jüngsten Update entsprechend darauf vor. Die größte Veränderung an der RTUv2 gegenüber der über drei Jahre genutzten RTUv1 betrifft die Hardware-beschleunigte Traversal-Berechnung direkt in der RTU anstatt im Compute-Shader der GPU. Traversal ist der Prozess, bei dem ein Strahl durch eine Beschleunigungsstruktur (zum Beispiel BVH oder KD-Tree) wandert, um herauszufinden, welche Objekte er trifft. Anstatt jeden Strahl mit jedem Dreieck in der Szene zu testen, was langsam und ineffizient wäre, nutzen moderne GPUs die Traversal durch eine hierarchische Datenstruktur. Arm (und andere Hersteller) setzen dafür auf eine Bounding Volume Hierarchy (BVH).


Single Ray Model statt Packed Ray Model
Die GPUs wechseln von dem bislang genutzten Packed Ray Model zu einem Single Ray Model. Bei einem Single Ray Model nimmt die GPU einen Strahl, berechnet seine Schnittpunkte mit der Szene (zum Beispiel BVH-Traversal) und gibt das Ergebnis zurück. Diese Art der Umsetzung ist einfach zu implementieren und flexibel, da unterschiedliche Strahlen sehr verschiedene Wege nehmen können, was für die GPU dennoch leicht zu handhaben ist. Nachteile soll diese Umsetzung bei Effizienz und Anzahl der Speicherzugriffe haben.
Beim Packed Ray Model werden die Strahlen zu Paketen gebündelt (bei Arm Immortalis bislang 16 Strahlen) und gleichzeitig verfolgt. Die Idee dahinter ist: Strahlen, die räumlich nahe beieinander liegen, durchlaufen oft ähnliche Teile der Szene. Dadurch lassen sich Traversal und Schnittberechnungen bündeln und die Parallelität und Effizienz steigern. Wenn Strahlen aber sehr unterschiedliche Wege nehmen, etwa nach vielen Spiegelungen, wird das Packed-Ray-Verfahren ineffizient. Außerdem handelt es sich um eine allgemein komplexere Implementierung.

Arm hält mit der RTUv2 und den neuen Mali-GPUs aber das Single Ray Model für die richtige Wahl. So kommt die Mali G1-Ultra mit inkohärenten Strahlen, also solchen, die sehr unterschiedliche Wege nehmen, besser zurecht und kann in diesen Szenarien für eine realistischere Beleuchtung und Reflexionen sorgen.
Doppelt so hohe Raytracing-Leistung*
Die im Endergebnis propagierte doppelt so hohe Raytracing-Leistung bezieht sich auf interne Raytracing-Microbenchmarks und Raytracing-Benchmarks. Spiele mit Raytracing-Unterstützung werden auf den neuen GPUs jedoch nicht doppelt so schnell laufen. In der intern genutzten Raytracing-Demo „Lumilings“ liegt der Zuwachs bei voller Qualitätsstufe bei 40 Prozent gegenüber einer Immortalis-G925 mit 14 Kernen. Arm wirbt zudem mit +17 Prozent in Genshin Impact, +11 Prozent in Fortnite, +25 Prozent in Arena Breakout und +26 Prozent in der eigenen Demo Mori.


Anzahl der RT-Einheiten wächst mit Shader Cores
Die Zahl der Ray Tracing Units steigt erneut mit der Menge der Shader Cores, sodass größere GPUs mehr Raytracing-Einheiten besitzen. Am Beispiel der Mali G1-Ultra 14-Core sind es somit 14 Ray Tracing Units. Die RTUv2 kommt diesmal zudem mit einer eigenen „Power Island“, befindet sich demnach in einem elektrisch separierten Bereich mit eigener Stromversorgung. Wird die Einheit nicht benötigt, soll sie auch keinerlei Strom verbrauchen, was der Gesamteffizienz der GPU zugutekommen soll.
GPU rendert effizienter bei Abhängigkeiten
Zu einem effizienteren Shader Core soll außerdem ein optimiertes Rendering bei sogenannten „Image Region Dependencies“ führen. Das sind Abhängigkeiten, die entstehen können, wenn verschiedene Regionen eines Bildes nicht unabhängig voneinander berechnet werden können. Das kann zum Beispiel bei Post-Processing-Effekten wie Bloom, Blur oder Depth of Field der Fall sein, da dort auf Nachbarpixel außerhalb der eigenen Region zugegriffen wird. Ein Tile kann also nicht fertig sein, bevor Nachbar-Tiles Ergebnisse geliefert haben. Hier soll das Scheduling bei mehreren Durchgängen jetzt effizienter ablaufen und zu weniger Leerläufen führen, da das Hochfahren eines neuen Durchlaufs schneller und überlappend mit dem Herunterfahren des vorherigen Durchlaufs erfolgen kann.
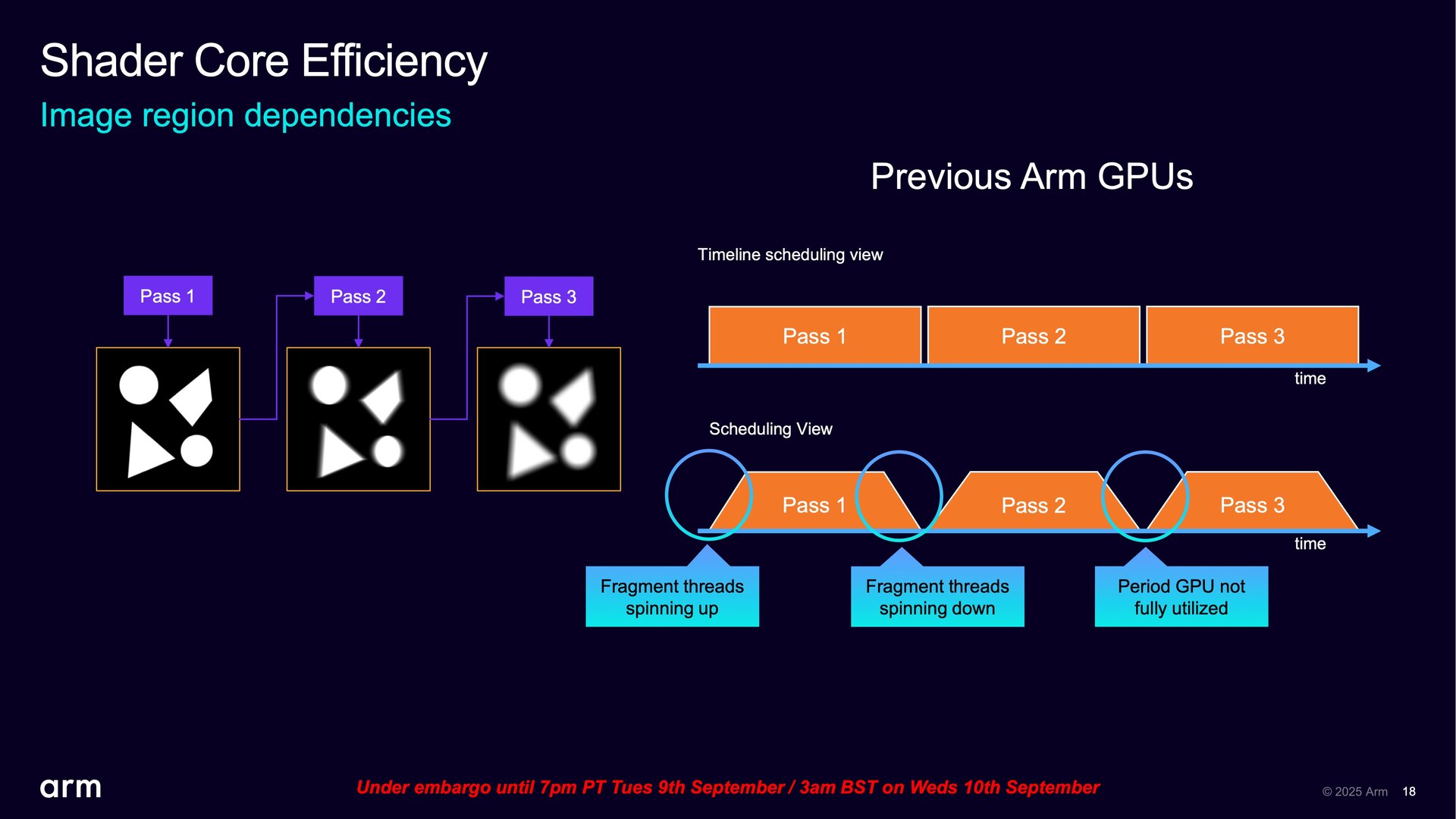

Leistung soll mit Komplexität wachsen
Weitere Veränderungen betreffen den Tiler, der entscheidet, welche Primitives in welchen Tiles landen. Dort fällt der „Position FIFO“ (First-In-First-Out), ein Zwischenspeicher für die Screen-Space-Positionen der Eckpunkte, ein Drittel größer aus, was mehr Positionsanfragen ermöglicht. Arm nennt zudem Optimierungen beim Index-Driven Vertex Shading (IDVS) und Compute Scheduling. Außerdem hat das Unternehmen die Anzahl der FAU-Register (Fast Access Uniform) verdoppelt, sodass mehr Register für Uniforms wie Transformation-Matrizen, Lichtparameter oder Materialkonstanten zur Verfügung stehen. Über Maßnahmen wie diese soll die GPU-Leistung mit der Komplexität der Inhalte Schritt halten.

Verdrahtung verdoppelt und L2-Slices neu verteilt
Die interne Verdrahtung einzelner GPU-Bereiche sei vereinfacht ausgedrückt zudem verdoppelt worden, um den allgemeinen Durchsatz in praktisch allen Bereichen zu steigern. Passend dazu hat Arm die Anzahl der L2-Cache-Slices verdoppelt, wobei diese Veränderung nicht gleichzusetzen ist mit einem doppelt so großen L2-Cache. Zuvor hat Arm zwei oder vier L2-Cache-Slices mit jeweils 256 KB, 512 KB oder 1 MB ermöglicht, wobei eine High-End-Konfiguration wie die Immortalis-G925 mit 4 MB L2-Cache ausgestattet war. Die Mali G1-Ultra bleibt bei 4 MB, verteilt den L2-Cache im überarbeiteten Top-Level-Netzwerk aber auf acht Slices à 512 KB.

Dual-Stack Shader Cores für mehr Leistung
Arm wechselt mit der Mali G1-Ultra (und den anderen Ablegern) außerdem zu sogenannten „Dual-Stack Shader Cores“ und will damit Bandbreite und Leistung steigern. Die Shader Cores sind nicht mehr durch einen einzelnen vertikalen Stack miteinander verbunden, bei dem Daten durch die Cores und Interconnects hoch und runter verlaufen, was potenziell zu Engpässen führen konnte. Der Dual-Stack-Aufbau sieht stattdessen zwei parallel verlaufende vertikale Pipelines für die Shader Cores vor, wobei jeder Stack seine eigenen internen Verbindungen besitzt. Die Verbindung erfolgt über Async Network Switches und Bridges. Zusätzliche Pipeline-Stufen sollen den Durchsatz über längere Pfade unterstützen. Geteilte Signale wie Takt, Reset und DFT (Design For Test) speisen beide Stacks.

AI mit MMUL.FP16 auf der GPU
AI auf der GPU spielt mit der neuen Mali-Generation ebenso eine Rolle. Die CPU sieht Arm zwar als erste Wahl für AI, wie die Integration neuer SME2-Beschleuniger im C1-CPU-Cluster verdeutlicht, aber auch die GPU kann für gewisse KI-Workloads zum Einsatz kommen. Bei der von Arm gewählten Auswahl von Inferencing-Workloads mit FP32 sollen die neuen Grafikeinheiten durchschnittlich 20 Prozent mehr Leistung liefern. Gänzlich neu ist die Unterstützung des Datenformats MMUL.FP16 (Matrix Multiply mit FP16-Präzision), das eine schnellere Tensor-Verarbeitung bei geringerer benötigter Speicherbandbreite ermöglichen soll.


ComputerBase hat Informationen zu diesem Artikel von Arm im Rahmen einer Veranstaltung des Herstellers in Cambridge, UK erhalten. Die Kosten für An-, Abreise und zwei Hotelübernachtungen wurden vom Unternehmen getragen. Eine Einflussnahme des Herstellers oder eine Verpflichtung zur Berichterstattung bestand nicht.