Qualcomm-Prozessor: Snapdragon X2 Elite mit drei Clustern und Matrix Engines
2/4Oryon 3 für Notebooks und Smartphones
Die CPU des Snapdragon X2 Elite Extreme entspricht der dritten Generation Oryon. So bezeichnet Qualcomm die eigens entwickelte Mikroarchitektur, die ihren Ursprung in der Übernahme von Nuvia vor bald fünf Jahren und deren Phoenix-Design hat. Die erste Generation kam im Snapdragon X Elite zum Einsatz, die zweite im Snapdragon 8 Elite und die dritte jetzt im Snapdragon X2 Elite (Extreme) und Snapdragon 8 Elite Gen 5.
Zwei Prime-Cluster + Performance-Cluster
Analog zum bislang angebotenen Notebook-Chip von Qualcomm verfügt die Oryon-3-CPU erneut über drei Cluster. Anstelle von vier identischen Performance-Kernen pro Cluster, wobei eines der drei Performance-Cluster mehr in Richtung Effizienz getrimmt war, kommen mit der neuen Generation zwei Prime-Cluster mit jeweils sechs Kernen und ein dediziertes Performance-Cluster, das auf Effizienz ausgelegt ist, mit ebenfalls sechs Kernen zum Einsatz, sodass eine CPU mit insgesamt 18 statt 12 Kernen geboten wird.
Das gilt für das Topmodell Snapdragon X2 Elite Extreme und den im Takt reduzierten Ableger ohne „Extreme“. Eine 12-Kern-Variante mit einem Prime- und einem Performance-Cluster wird ebenfalls angeboten.
-
 Snapdragon X Series Architecture Deep Dive – CPU (Bild: Qualcomm)
Snapdragon X Series Architecture Deep Dive – CPU (Bild: Qualcomm)


Eine Matrix Engine zieht in jedes Cluster
Neu ist darüber hinaus, dass jedes Cluster neben den klassischen CPU-Kernen über eine dedizierte Matrix Engine für die Scalable Matrix Extension der Arm-ISA verfügt. SME ist eine Erweiterung der Arm-Architektur und wurde entwickelt, um den Prozessor bei genau der Art von Rechenarbeit schneller zu machen, die in KI, Machine Learning, Bild- und Audiosignalverarbeitung ständig vorkommt – nämlich große Matrizen von Zahlen zu verschieben, zu multiplizieren und zu addieren. Später mehr zu den Matrix Engines.
Die Oryon-3-Mikroarchitektur im Detail
Neben der neuen Matrix Engine hat Qualcomm mit der Oryon-3-Mikroarchitektur Verbesserungen an der Sprungvorhersage, den Load-Store-Einheiten, dem Prefetching und mehr vorgenommen. Es handele sich um ein breiteres und schnelleres Design.
Decode- und Rename-Stufe wachsen auf „9-wide“
Die Mikroarchitektur von Oryon 3 lässt viele Parallelen zur Mikroarchitektur von Oryon 1 erkennen, in vielen Bereichen sind die CPUs sogar identisch aufgebaut. Das breitere Design lässt sich anhand der Decode-Stufe erkennen, wo jetzt neun anstelle von acht Decodern zum Einsatz kommen. Die Decode-Stufe ist eine der zentralen Phasen in der Pipeline einer CPU-Mikroarchitektur. In dieser Stufe wird eine zuvor geladene Maschineninstruktion interpretiert, also in interne Steuersignale und Operanden zerlegt, sodass die CPU weiß, was genau ausgeführt werden soll. Bei Oryon 3 werden somit neun Mikrobefehle pro Zyklus an das Backend entsendet. Bei einer CPU mit maximal 5,0 GHz entspricht ein Zyklus 0,2 Nanosekunden (0,000000002 s).
-
 Snapdragon X Series Architecture Deep Dive – CPU (Bild: Qualcomm)
Snapdragon X Series Architecture Deep Dive – CPU (Bild: Qualcomm)

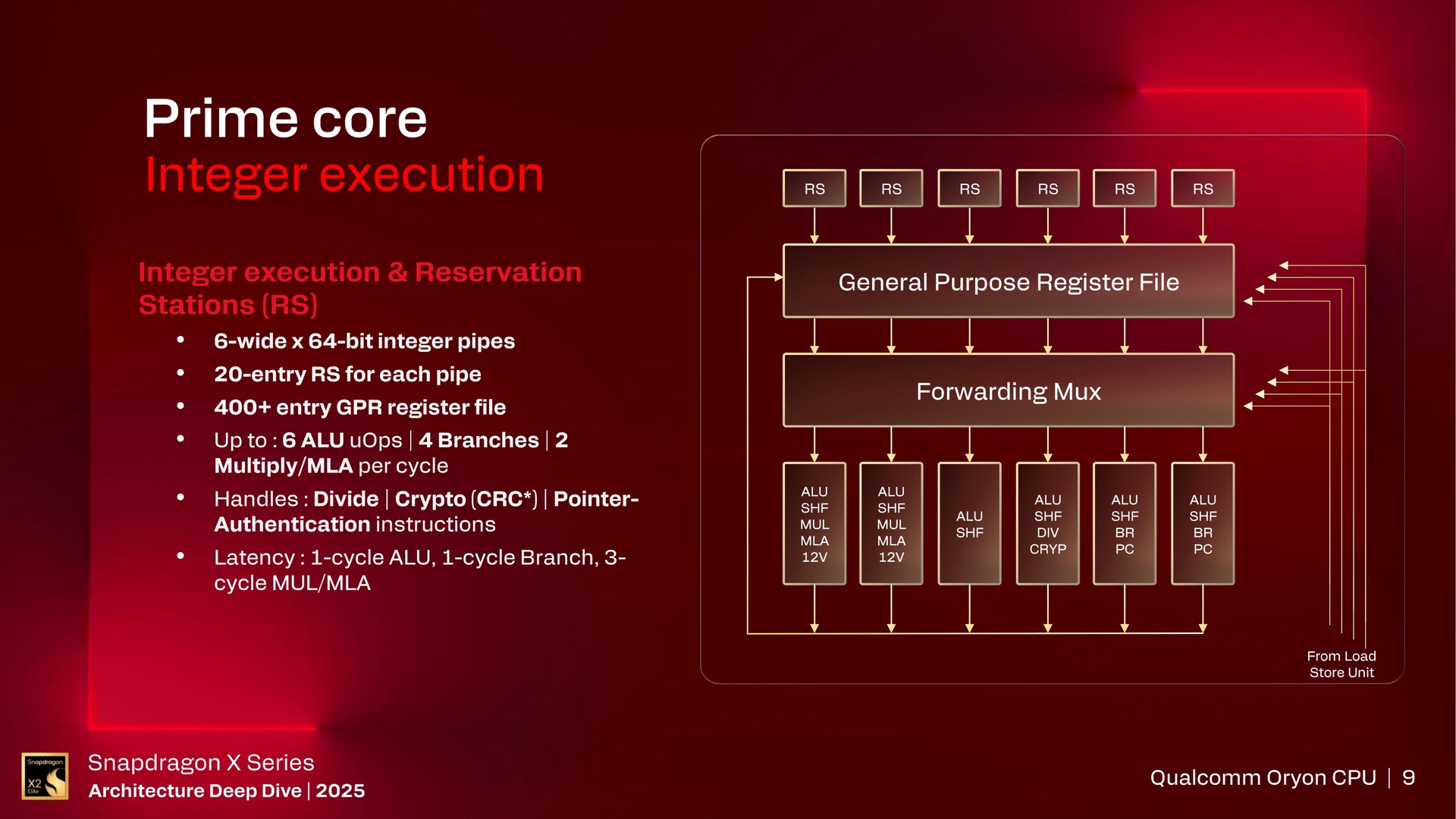
Passend zur Decode-Stufe hat Qualcomm die Rename-Stufe auf „9-wide“ umgestellt. Die Rename-Stufe weist Architekturregister neuen physischen Registern zu, um falsche Abhängigkeiten zu vermeiden, während die darauffolgende Dispatch-Stufe die umbenannten Instruktionen in die passenden Ausführungswarteschlangen einordnet und an die jeweiligen Funktionseinheiten weitergibt. Die Mikrobefehle werden bei Oryon 3 an insgesamt 14 Ausführungswarteschlangen (Reservation Stations) weitergeleitet: 6 Integer, 4 Vector und 4 Load-Store. Bei der Dispatch-Stufe ist Oryon 3 somit identisch zu Oryon 1 aufgestellt.
Oryon 3 verfügt pro Kern erneut über getrennte Funktionseinheiten für Integer (1) sowie Vector, SIMD und Floating Point (1). Diese Einheiten sind identisch zu Oryon 1 aufgebaut. Die Instruction Execution Unit (IXU) für Integer ist „6-wide“ mit jeweils 20 Einträgen in den Reservation Stations und 400+ Einträgen in der General Purpose Register File. In der „4-wide“ Vector Execution Unit (VXU) sind es 48 Einträge pro Pipe und ebenfalls 400+ Einträge in der Vector Register File.
-
 Snapdragon X Series Architecture Deep Dive – CPU (Bild: Qualcomm)
Snapdragon X Series Architecture Deep Dive – CPU (Bild: Qualcomm)




Die Load-Store-Einheiten kümmern sich darum, Daten aus dem Speicher zu laden (Load) oder in den Speicher zu schreiben (Store), ohne die ALUs zu blockieren. Dazu berechnen sie effektive Adressen, verwalten die Load/Store-Queues, führen Zugriffe über den Cache-Hierarchiepfad aus und sorgen für die korrekte Reihenfolge bei Speicherabhängigkeiten. Die LSU ist somit das Interface zwischen Rechenpipeline und Speicher – sie berechnet Adressen, koordiniert Cache-Zugriffe und garantiert korrekte, geordnete Speicheroperationen auch während der Out-of-Order-Ausführung.
Matrix Engines mit 8×8- und 4×8-Grid
Vollständig neu ist die Matrix Engine, von der sich eine in jedem Prime- und Performance-Cluster findet. Qualcomm beschreibt sie als Matrix- und ML-Beschleuniger direkt in der CPU. Diesen Ansatz verfolgt auch Arm selbst, zuletzt bei den neuen C1-Kernen mit SME2. Neben NPU, GPU und den eNPUs im Sensing Hub gibt es im SoC damit einen weiteren Funktionsblock für KI-Workloads.
Qualcomms Matrix Engine fällt je nach Cluster unterschiedlich groß aus. In den beiden Prime-Clustern besteht diese aus einem 8×8 großen „Grid“, also der logischen Anordnung von Recheneinheiten, die zusammen eine Matrixoperation ausführen. Jedes Element im Grid kann eine kleine Operation ausführen, etwa eine Multiplikation oder Addition eines Matrixelements. Durch das Grid werden viele Matrix-Operationen parallel bearbeitet.

Im kleineren Performance-Cluster kommt eine kleinere Matrix Engine mit 4×8-Grid zum Einsatz. Jede Matrix Engine kann mit den Datentypen BF16, FP16, FP32, INT8, INT16 und INT32 umgehen. Die Matrix Engine läuft zudem unter einer eigenen Clock-Domain, um Verbrauch und Abwärme unabhängig von den CPU-Taktraten steuern zu können.
50 Prozent kleinerer Performance-Kern
Die Mikroarchitektur von Oryon 3 im Performance-Cluster fällt reduziert aus. Qualcomm nannte zum Architecture Day in San Diego eine „ähnliche“ Out-of-Order-Mikroarchitektur wie bei den Prime-Kernen, die aber weniger breit und mit weniger Ausführungseinheiten, geringerer Tiefe und kleineren Caches bestückt sei. Den L2-Cache hat Qualcomm auf 12 MB angepasst. Das Design sei für einen niedrigeren Verbrauch und einen kleineren physischen Fußabdruck auf dem Die ausgelegt. 50 Prozent kleiner als ein Prime-Core sei der Performance-Core, wie es auf Nachfrage hieß. Das Design operiere besonders effizient im Bereich unter 2 Watt. Unter Volllast im Cinebench 2024 konnte die Redaktion jedoch bis zu 6 Watt für das Performance-Cluster ermitteln.


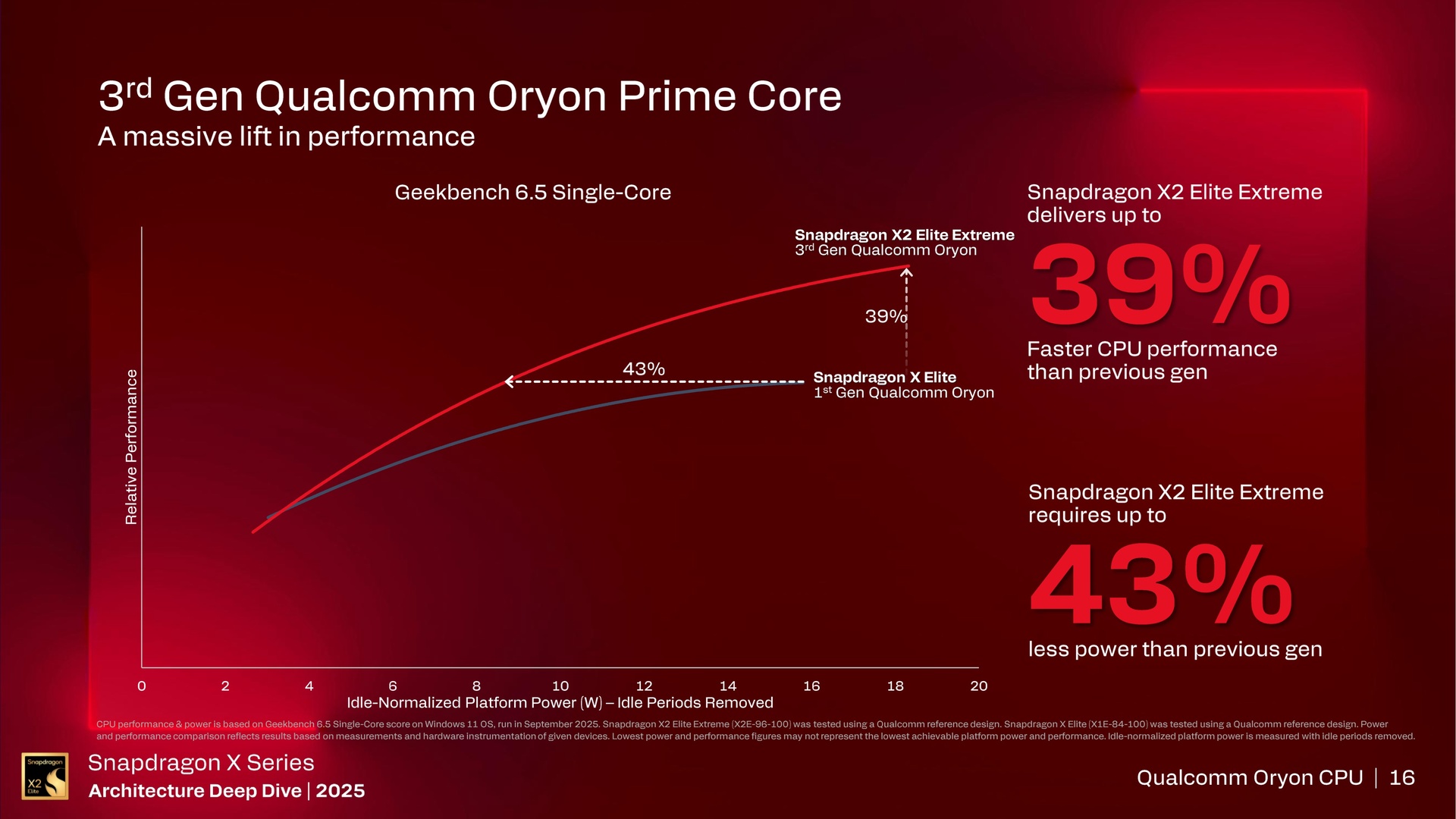
39 Prozent höhere Single-Core-Leistung
Zwei Kennzahlen bei Single-Core-Last verdeutlichen die Fortschritte gegenüber Oryon 1. Qualcomm gibt für den Geekbench 6.5 eine bis zu 39 Prozent höhere Single-Core-Leistung sowie bei gleicher Leistung einen 43 Prozent niedrigeren Verbrauch gegenüber dem X1E-84-100 (Test) an. Erste CPU- und GPU-Benchmarks mit dem Snapdragon X2 Elite Extreme konnte die Redaktion bereits zur Vorstellung Ende September durchführen. Zum Architecture Day waren auch Benchmarks mit den kleineren Modellen möglich. Die Benchmark-Ergebnisse hat die Redaktion in einen eigenständigen Artikel ausgelagert.
Taktraten hängen von aktiven Kernen ab
Qualcomm nennt für den größten X2E-96-100 bis zu 5,0 GHz Boost auf zwei Prime-Kernen und bis zu 4,4 GHz Multi-Core-Boost. Das ist so weit auch korrekt, im Detail hängt der Takt innerhalb eines Clusters jedoch von der Anzahl der aktiven Kerne ab.

Der „Cluster-Level Multi-Level Boost“, wie Qualcomm das Feature beschreibt, sieht innerhalb eines Prime-Clusters bei einem aktiven Kern maximal 5,0 GHz vor. Bei zwei aktiven Kernen sind es 4,8 GHz, bei drei Kernen 4,47 GHz und bei vier, fünf oder sechs aktiven Kernen 4,45 GHz. Weil die Taktregelung unabhängig pro Cluster erfolgt, sind über die zwei Prime-Cluster jeweils 5,0 GHz auf einem Kern möglich. Der Performance-Cluster bietet keinen Boost und kommt beim Single- und Multi-Core-Takt auf 3,6 GHz.