Nvidia-Generationenvergleich: Benchmark-Ergebnisse im Überblick
2/4Spielleistung im Überblick
Auch in diesem Vergleich soll grob auf die technischen Unterschiede zwischen den verschiedenen RTX-Generationen eingegangen werden und ebenso wie bisher muss dafür zuerst ein Blick auf die Leistungsdaten der verschiedenen Grafikkarten geworfen werden.
Auch dieses Mal zeigt sich, dass moderne Grafikkarten in 1080p in der Regel weniger stark zulegen können als in 2160p.
Leistungszuwachs ohne RT
In 1080p kann sich die RTX 5070 im Mittel um magere 21 Prozent absetzen, in 2160p sind es etwas bessere 26 Prozent, gegenüber dem Sprung zwischen der RTX 2070 und 3070 von 53 sowie starken 69 Prozent ist das aber deutlich weniger. Die RTX 4070 sortiert sich mit 35 und 39 Prozent dazwischen ein.
Leistungszuwachs mit RT
In Raytracing dreht sich das Bild etwas, was an den 8 GB VRAM von RTX 2070 und RTX 3070 liegt. Zwischen diesen beiden Grafikkarten liegen in Full HD gute 54 Prozent und in 2160p beachtliche 76 sowie 90 Prozent. Blackwell bewegt sich bei der Steigerung erneut am unteren Ende mit mageren 16 Prozent in Full HD und UHD. Etwas Interessantes offenbart sich, wenn ein Blick auf die Effizienz geworfen wird. Anzumerken ist jedoch, dass für die Effizienzbetrachtung in diesem Test die Werte des Monitorings verwendet werden, das seit Ada immer etwas zu wenig Leistungsaufnahme meldet.
Bei der Effizienzbetrachtung gibt es in diesem Test zwei Szenarien, die eintreffen: Die Effizienzsteigerungen in Raytracing und bei Raster sind immer unterschiedlich und ebenso gibt es Unterschiede bei den Auflösungen. Ampere steigert die Effizienz bei Raytracing um 54 Prozent in 2160p und deutlich geringere 33 Prozent in 1080p. Diese Steigerungen liegen allerdings über denen im Rasterizer-Teil des Generationenvergleichs mit 24 und 34 Prozent in Full HD und 4K.
Auch Ada Lovelace kann die Effizienz in RT noch einmal deutlicher steigern als bei Rasterizer, gleichzeitig dreht sich das Bild bei den Auflösungen: Die Effizienzsteigerungen sind nun in 1080p mit 80 Prozent gegenüber 74 Prozent in 2160p bei Raytracing unterschiedlich, während bei Rasterizer 50 Prozent herumkommen. Blackwell wiederum? Es ist kompliziert. Bei Rasterization agiert Blackwell vier Prozent effizienter als Ada Lovelace, bei Raytracing wiederum ist Ada Lovelace in 1080p genauso effizient und in 2160p sogar sechs Prozent effizienter.
Die technischen Hintergründe
Turing – Integer? INTEGER!
Auf die Änderungen zwischen Pascal und Turing wurde im vorherigen Generationenvergleich eingegangen und damit ist Turing (Whitepaper, PDF) dieses Mal die Ausgangslage.
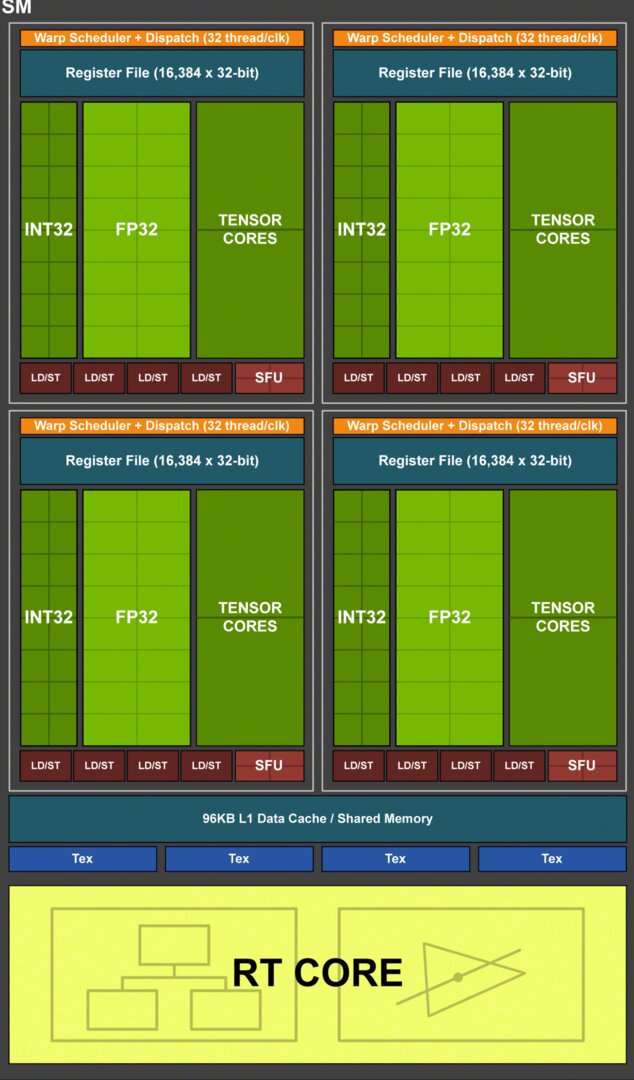
Um Turing für moderne Spieleworkloads zu optimieren, hat Nvidia den grundlegenden Aufbau von Pascal beibehalten, hat die 32 Shader allerdings in 2 Blöcke a 16 Shader umorganisiert. Ein Block berechnete dabei Operationen für Floatingpoint-Werte, der andere Block die Operationen für Integer-Werte. Neben diesen Änderungen zogen in jede Kachel zwei Tensor-Kerne ein, die Matrizen-Operationen beschleunigen, und in die SM die erste Generation der RT-Kerne.
Ampere – Floatingpoint im Overdrive
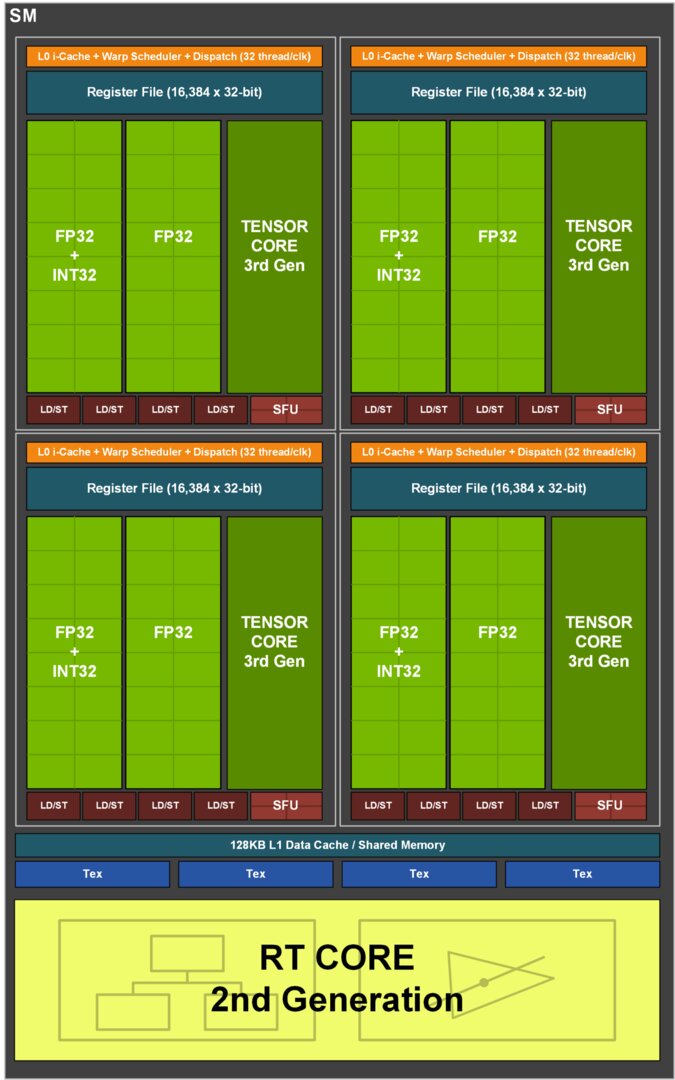
Ampere (Whitepaper, PDF) ist in gewisser Form ein Turing-Refresh, denn die Änderungen halten sich in Grenzen und entsprechendes offenbart auch das Blockdiagramm. Es gibt allerdings zwei Änderungen, die Nvidia auch prominent hervorgehoben hat.
Der zweite Shader-Block aus 16 Shader kann nun neben Integer auch Floatingpoint-Werte berechnen, wodurch die FP-Leistung mit Ampere stark gesteigert werden konnte. Die zweite Änderung betrifft die Tensor-Kerne. Statt zwei gibt es nur noch einen pro Kachel, gleichzeitig hat die Leistungsfähigkeit dieses einen Kernes stark zugenommen.
Ada Lovelace – Raytracing-Monster

Auch bei Ada Lovelace ist die Verwandtschaft zu Turing zu erkennen, denn es gab an der SM dieses Mal keine grundlegenden Änderungen, aber Anpassungen im Detail. Eine SM besteht weiterhin aus vier Kacheln, die aus einem Warp-Scheduler, Register-File sowie 32 Shadern besteht, die in zwei 16er-Blöcken organisiert sind. Dazu ein Tensor-Kern und die Load- and Store-Einheiten. Die SM selbst beinhaltet vier Textureinheiten, einen 128 KB großen L1-Cache für alle vier Kacheln und den neuesten RT-Kern. Der RT-Kern wurde dabei um neue Funktionen erweitert. Es geht dabei um die Opacity-Micromap-Engine sowie um die Displaced Mirco-Mesh Engine. Nvidia geht dabei auf die Funktionen im Ada-Lovelace-Whitepaper (PDF) entsprechend ein. Beides sind Detail-Verbesserungen, die die RT-Leistung erhöhen.
Gleichzeitig gibt es mit Raytracing ein Problem, das Nvidia mit Ada Lovelace angegangen ist: Während bei Rasterizing die Shader in der Regel „perfekt“ sortiert vorliegen, kann es beim Raytracing passieren, dass die Shader ungeordnet vorliegen und damit die Shader-Einheiten nicht mehr optimal ausgelastet werden. Um dieses Problem zu lösen, hat Nvidia die Shader Execution Reordering (SER) entwickelt.
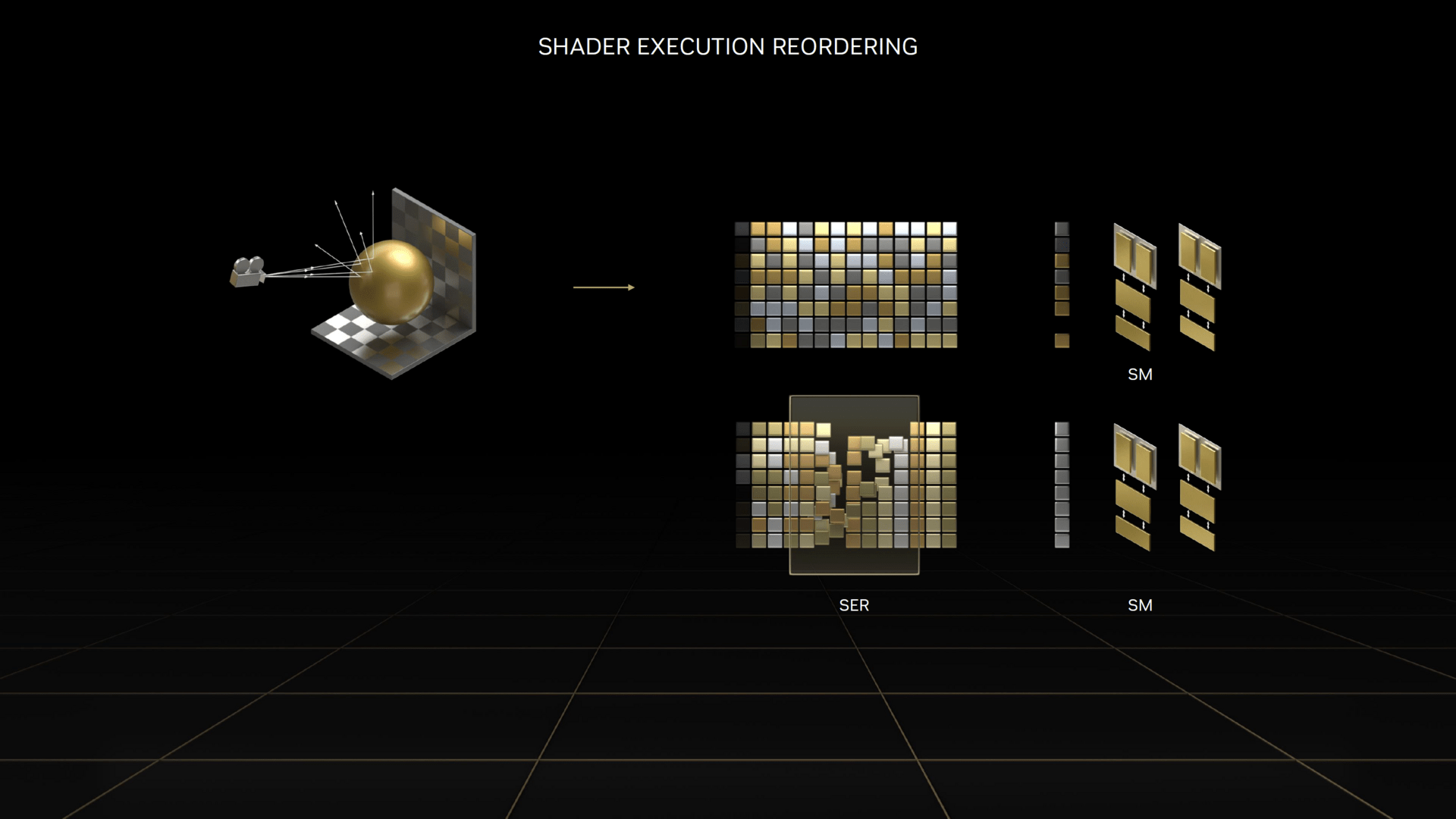
Bisher war SER nvapi exklusiv, ist seit Ende Mai jedoch als Preview für die kommende DXR-Version 1.2 verfügbar und wird Bestandteil der Shader-Model 6.9. Daneben ziehen in DXR 1.2 auch die Opacity Micromaps ein.
Blackwell – Pascal ist zurück, irgendwie
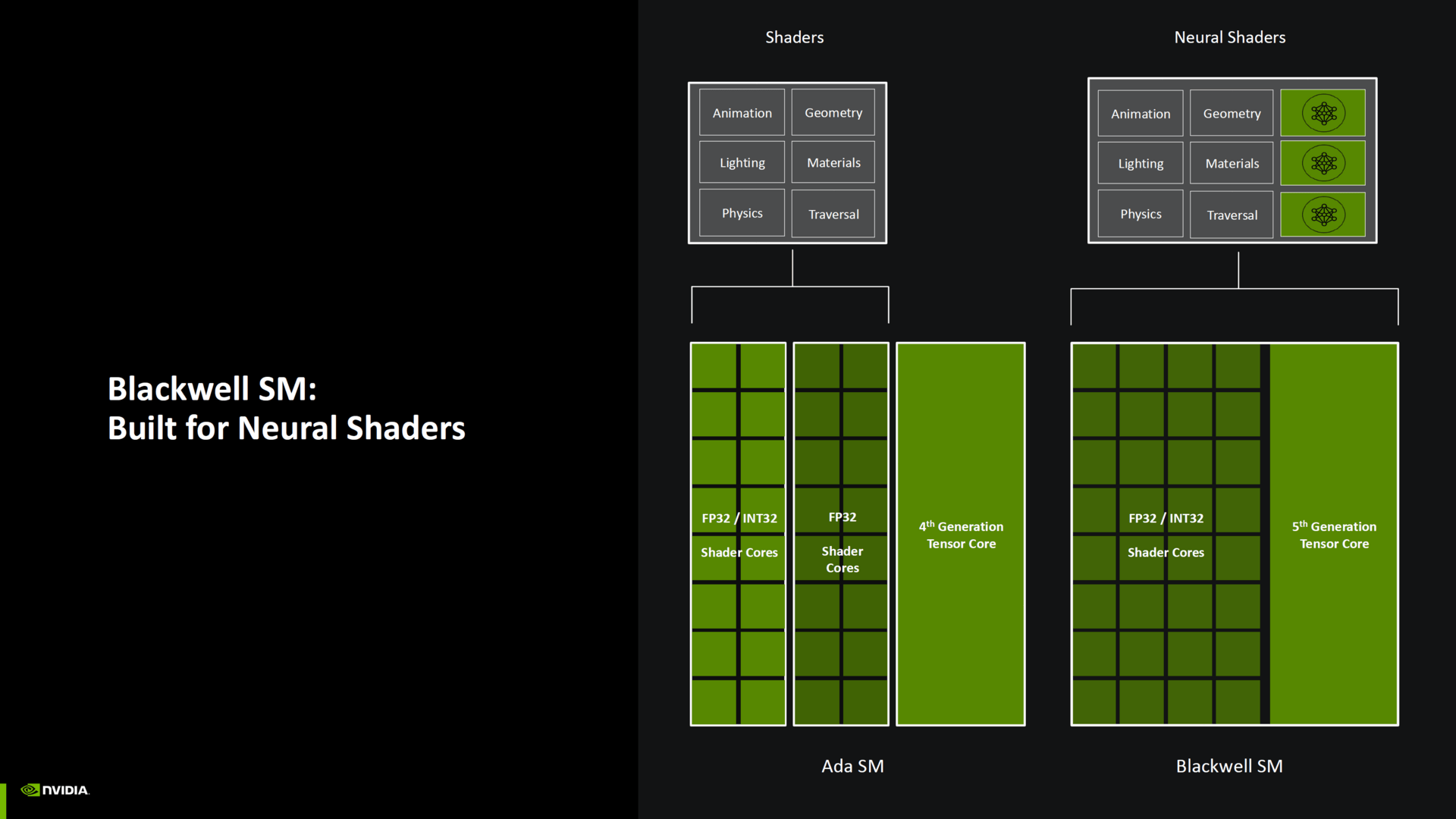
Blackwell (Whitepaper, PDF) verliert bei den SM eine Fähigkeit, die mit Turing eingeführt wurde: die Ausführung von einer INT- und FP-Operation zur gleichen Zeit. Stattdessen werden nun die bisher in zwei 16er-Blöcken organisierten Shader wieder in einem 32er-Block organisiert. Gleichzeitig betont Nvidia, dass jetzt doppelt so viele Integerberechnungen ausgeführt werden können. Mehr Leistung für künstliche Intelligenz und die vorgestellten Neural-Shader.