Quidproquo77 schrieb:
Dann nenne es halt "AI accelerators", die 7900XTX hat zwei je CU, sprich 192. Dennoch kein gleichwertiges Tensor Äquivalent.Die haben die Karte auch nicht davor bewahrt nun durchgereicht zu werden.
Matrix cores gibts es NUR bei den CDNA Karten der MI200 und MI300 Serie.
AMD hat nie gesagt, dass die 7000er Gen irgendwas in Richtung Tensor Core und deren Leistung mitbringt, daher ist dein zusammengegoogeltes Argument wenig standhaft. WMMA sind Instruktionen um GEMM auszuführen und das performanter als die vorherige Generation.
Die RDNA Karten haben AI accelerator, was aber im RDNA 3 Fall keine eigenen Cores oder Units sind, sondern das WMMA instruction set.
https://gpuopen.com/learn/wmma_on_rdna3/
Quidproquo77 schrieb:
Es gibt demnach also viele Dinge die man auch andersrum kritisch sehen muss bzw. kann. Was nützt es dann immer so einseitig auf etwas herumzureiten, was bei der Konkurrenz eh nicht besser ist?
Es gibt vor allem Dinge, zu denen man sich belesen sollte, bevor man den großen Rant beginnt. WÄRE dem tatsächlich so, wären diverse Techseiten ( auch CB, GN, HWU usw. ) damals schon drauf angesprungen und hätten mit großer Resonanz Videos dazu gemacht.
Quidproquo77 schrieb:
Das ist ein Phänomen das beide Hersteller wie alle anderen auch zum Launch der Produkte nutzen um damit viele Menschen zu erreichen. Ankündigungen, Gerüchte, irgendwelche geschönten Folien. Und?
Nvidia hat sich dazu gar nicht in der Form geäußert, noch würden sie irgendetwas davon haben, da sie auch nur das zu den vereinbarten und festgelegten Preisen an die Boardpartner ausliefern können, was sie auch produzieren können und bei TSMC in Auftrag gegeben haben bzw. als Kontingent erhalten haben.
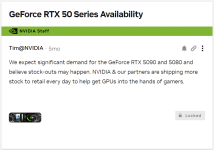
Und genau das hat nVidia kurz vorher gemacht. Man hat bewusst gesagt, dass man "stock-outs" erwartet und Blackwell teurer wird.
Dazu hat man schon Mitte 2027 angefangen die Produktion im Mid- und Highend Bereich zurückzufahren, damit sich die Lager leeren. Führt am Ende zur schlechten Verfügbarkeit, bleibenden oder steigendem Preis und einen Run auf die letzten Karten. Dazu kam Blackwell deutlich zu teuer in zu geringer Stückzahl, was den Run auf beide Gens nochmal befeuert.
Man war sich dessen absolut bewusst - nVidia weiß ganz genau, was die Folgen ihres Handelns sind.
Das jeder Post von großen Herstellern bei X landet oder medial verarbeitet wird, weiß doch jedes Kind und so war es hier auch. Das
Jetzt zeig mir bitte ein Mal WANN und WO so eine Nummer bei AMD so durchgezogen wurde.
Quidproquo77 schrieb:
Genau, falsche Versprechen gibt es per Definition nur bei Nvidia.^^
Das stimmt so nicht und deine Antwort ist wie die eines trotzigen Kindes. Kein Argument, kein Beleg, keine Fakten.
Es ging hier rein um das Leistungsversprechen, welches es bei AMD im Vergleich zu nVidias Blackwell mit geschönten kruden Benchmarks nicht gab. Sollte dem doch so sein - bitte her damit.
nVidia daggen hat sehr alter Gens vs Blackwell mit 2x, 3x, 4x MFG gestellt damit man tolle Balken generiert.
Wenn ich jetzt noch mehr alte Folien rauskrame von nVidia, findet sich sicher noch mehr solcher Nummern retrospektiv.
Quidproquo77 schrieb:
Ah und woran liegt das wohl?
Liegt einfach daran, dass RDNA 3 kein natives fp8 kann.
RDNA 4 kann nativ fp8 und FSR 4 braucht natives fp8.
Die Folge ist, dass man FSR 4 (fp8) nur via fp16 Emulation ( es gibt einen Patch mit Workaround unter Linux ) auf RDNA 3 ( ev. sogar auf 1 und 2 )
zum Laufen bekommt, aber eben weniger performant.
Grund hierfür ist zum einen die fp8 via fp16 Emulationm die Performance und Zeit kostet.
Ein weiterer Grund ist der generell niedrigere ML/AI Durchsatz bei RDNA 3, da im Vergleich zu RDNA 4 keine ded. AI Cores vorhanden sind.
Quidproquo77 schrieb:
Mit dem richtigen Knick in der Optik geht alles.
Naja, viel sagen mit wenig Inhalt und leeren ( vor allem scheinbar selbst mit zu beantwortenden ) Gegenfragen deinerseits ist auch eine Art und Weise damit umzugehen. Und wenn mal garkein Argument kommt, hilft ja immernoch die trotzige Abwehrhaltung - siehe oben.
Schönen Tag noch.